前提知識
- React:インタラクティブな Web フロントエンド(クライアント上で稼働する Javascript)を実装するためのライブラリーで、状態変数の値の変化を自動的に画面に反映する機能があります。
- Firebase:モバイルアプリのバックエンドを Google Cloud で提供するサービスで、ユーザー認証やユーザー管理などの機能を専用のライブラリで簡単に実装できます。
- Cloud Run:アプリケーションのコンテナイメージを Google Cloud 上にデプロイして実行するサーバーレスタイプのサービスで、オートスケールなどの機能が簡単に利用できます。
なんの話かというと
上記の3つの技術(サービス)を組み合わせて、
- エンドユーザーは、Google アカウントで Web アプリケーションにログインする
- Web アプリケーションから Cloud Run で稼働するバックエンド API を実行する
- バックエンド API は、ログイン済みのユーザーからのリクエストのみを受け付ける
という要件を満たす Web アプリケーションのサンプル実装を作ったので、実装上のポイントを解説します。
github.com
サンプルを実際に利用する手順は、GitHub 上の README にありますが、ここでは、手順の各ステップについてポイントとなる部分を説明していきます。
Firebase の利用準備
Firebase は Google Cloud をバックエンドに使う前提なので、はじめに Google Cloud の利用登録をして、Google Cloud のコンソールから、Google Cloud のプロジェクトを作成する必要があります。その上で、Firebase のコンソールから、作成したプロジェクトを Firebase に登録して、利用する機能(今回の場合は、Google アカウントによるユーザー認証)の有効化やこれから作成するアプリケーションの登録などを行います。手順の「Do this first」では、この部分の作業を行ないます。
バックエンド API を Cloud Run にデプロイする
バックエンド用のアプリケーションは、Python の Flask というフレームワークで実装してあります。手順の「Build and deply the backend API service.」では、Google Cloud 上でコンテナイメージをビルドして、Cloud Run の環境にデプロイしています。アプリケーションの内容は単純で、
{"name": "Etsuji Nakai"}
というデータを受け取って、
{"message": "Hello, Etsuji Nakai!"}
というメッセージを返すものになります。ただし、重要な要件として、「ログイン済みのユーザーからのリクエストのみを受け付ける」という機能を満たす必要があります。これは、次のように、API を実装する関数 hello() に対して @jwt_authenticated というデコレーターを付与することで実現しています。
from middleware import jwt_authenticated
@app.route('/hello-world-service/api/v1/hello', methods=['POST'])
@jwt_authenticated
def hello():
...
デコレーターの中身は、middleware.py で実装されており、デコレーションした関数を実行する前に、API リクエストのヘッダーに Firebase が発行したユーザー ID トークンが含まれていることを検証します。実際に検証する部分は、Firebase が提供するライブラリ firebase_admin を使用しており、次の関数を実行するだけで検証ができます。
firebase_admin.auth.verify_id_token(token)
フロントエンドをビルドする
次は Web フロントエンドをビルドする部分になります。手順の「Build React Application.」の部分にあたります。React のコードは、JSX と呼ばれる形式で書かれており、これを Javascript 用のコンパイラ Babel を用いてブラウザーで実行可能な Javascript に変換します。Babel は Node.js を用いて実行されるので、手順の中では、Node.js をインストールした後にビルドを実行するという流れになります。ビルド済みのファイルは /build 以下に保存されます。
ビルド作業自体はとても簡単なのですが、重要なのはコードの中身なので、ポイントとなる部分を解説しておきます。
まずは、Firebase.js では、Firebase の基本的な設定情報を用意しています。
Firebase.js
import { initializeApp } from "firebase/app";
import { getAuth, GoogleAuthProvider, signInWithPopup } from "firebase/auth";
const firebaseConfig = {
...(省略)...
};
const app = initializeApp(firebaseConfig);
export const auth = getAuth(app);
const provider = new GoogleAuthProvider();
export const signInWithGoogle = () => {
signInWithPopup(auth, provider)
.catch((error) => {console.log(error)})
};
export const projectId = firebaseConfig.projectId;
手順の中でも説明しているように、変数 firebaseConfig には、Firebase にアプリケーションを登録した際に発行された各種情報をコピペで書きこんでおきます。これらの情報はアプリケーションがクラウド上の Firebase の機能を利用する際に必要となります。
ここでは特に、変数 auth に格納されたオブジェクトが重要になります。このオブジェクトを用いて、ログインユーザーの情報を管理することができます。また、関数 singInWithGoogle は、Google アカウントによるログイン画面をポップアップ表示して、エンドユーザーにログイン処理を行なってもらう際に利用します。
次に、App.js がアプリケーションの本体です。ここでは特に、次の部分がポイントになります。
App.js
userAuthHandler(user) {
if (user) {
this.setState({loginUser: user});
} else {
this.setState({
loginUser: null,
message: "no message"
});
}
}
componentDidMount() {
onAuthStateChanged(auth, this.userAuthHandler);
}
componentDidMount() は、ブラウザ上でアプリケーションが実行されたタイミングで、ハンドラー関数 userAuthHandler() を登録しています。このハンドラーは、エンドユーザーがアプリケーションにログイン、もしくは、ログアウトしたタイミングで自動的に実行されます。この例では、ログインしたタイミングで、React の状態変数 loginUser にユーザー情報を記録しています。あるいは、ログアウトしたタイミングでこの情報を削除します。冒頭で説明したように、React は、状態変数の値が変化すると自動で画面の再描画が行われるので、これによって、ログイン中の画面とログイン前(ログアウト後)の画面を切り替えています。(このあたりは、React の本当に便利な所ですね・・・。変数を書き換えれば勝手に画面も書き変わるとは・・・。)
次にポイントになるのは、バックエンド API を呼び出す次の関数 getMessage() です。
getMessage() {
const callBackend = async () => {
const baseURL = "https://" + projectId + ".web.app";
const apiEndpoint = baseURL + "/hello-world-service/api/v1/hello";
const user = auth.currentUser;
const token = await user.getIdToken();
const request = {
method: "POST",
headers: {
"Authorization": "Bearer " + token,
"Content-Type": "application/json",
},
body: JSON.stringify({
name: user.displayName,
})
};
fetch(apiEndpoint, request)
.then((res) => res.json())
.then((data) => this.setState({message: data.message}));
};
const waitMessage = new Promise(resolve => {
this.setState({message: "Wait..."});
resolve();
});
waitMessage.then(callBackend);
}
非同期処理をチェーンしているのでちょっと読みづらいですが、画面上のメッセージ表示部分を「Wait...」に書き換えた後に、非同期でバックエンド API を呼び出しています。バックエンド API からメッセージが返ってくると、その内容を状態変数に message に書き込みます。これによって、画面上のメッセージ部分にバックエンド API から受け取ったメッセージが表示されます。
バックエンド API を呼び出す際は、次の部分で取得したユーザー ID トークンをヘッダーに埋め込んでいます。
const user = auth.currentUser;
const token = await user.getIdToken();
前述のように変数 auth を用いてログインユーザーの情報が管理されており、ここでは、auth.currentUser でログイン中のユーザー情報を取得して、さらに、user.getIdToken() で該当ユーザーの ID トークンを取得しています。これは、Firebase が独自に発行するトークンで、有効期限が切れると自動的に新しいトークンが発行されます。つまり、user.getIdToken() でトークンを取得するようにしておけば、自分で有効期限を管理する必要はありません。
フロントエンドを FIrebase Hosting にデプロイする
ビルドされたアプリケーションは、普通の(?)Javascript なので任意の環境にデプロイすることができますが、この手順では、Firebase 標準の Web ホスティング環境である Firebase hosting にデプロイしています。具体的な手順は、「Deploy the application on Firebase hosting.」の部分になります。
Firebase hosting を利用するメリットの1つに Cloud Run との連携機能があります。Cloud Run の環境はセキュリティ強化のためにデフォルトでは CORS が禁止されています。CORS が禁止されているというのは、バックエンド API が稼働するドメインとは異なるドメインからのリクエストを拒絶するということで、Google Cloud 上で稼働するアプリケーション以外からのリクエストは受け付けないということです。アプリケーションの設定で CORS を許可することもできますが、Firebase hosting を利用した場合は、Firebase hosting の環境が Cloud Run に対する Proxy として動作することで、外部のクライアントから Cloud Run で稼働するバックエンド API が利用可能になります。
手順の中で、Firebase hosting の設定ファイル Firebase.json を書き換えているのは、このためで、具体的には次の部分が対応します。
"rewrites": [
{
"source": "/hello-world-service/**",
"run": {
"serviceId": "hello-world-service",
"region": "us-central1"
}
}
]
この設定により、Firebase hosting 上のアプリケーションのパス 「https://www.[Project ID].web.app/hello-world-service/」以下にリクエストを投げると、指定された Cloud Run のサービスにリクエストが転送されます。この際、Cloud Run と同じドメインからリクエストが転送されるので、CORS の制限を回避してバックエンド API の処理が行われます。
アプリケーションを試してみる
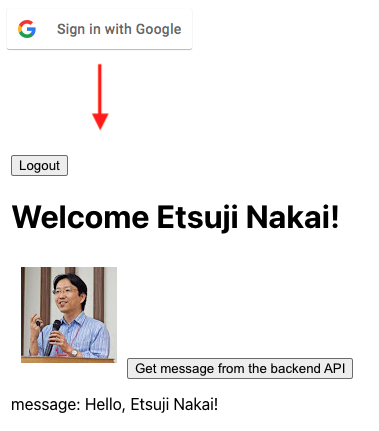
Firebase hosting にデプロイしたアプリケーションにアクセスすると「Sign in with Google」のボタンが出るので、これを押して、Google アカウントでログインします。すると、Google アカウントに設定されたプロフィール情報から取得した名前とプロフィール画像が表示されます。さらに、「Get message from the backend API」のボタンを押すと、バックエンド API からメッセージを取得します。「Logout」ボタンでログアウトした後に、他の Google アカウントで再ログインすることもできます。







")

")

")

 (English Edition)")
")
")
{kind=link}